Why AI Agents Need Trust Engineering, Not Just Better Code
You built an AI agent. It works. It automates tasks. It saves time.
Then it hallucinates a customer email. Or approves a refund it shouldn't. Or makes a decision you can't explain to your boss.
The problem isn't the model. It's that AI agents operate in a trust vacuum.
When you hand decision-making power to an autonomous system, you're not just shipping software anymore. You're delegating judgment.1 And judgment without guardrails becomes liability.3
Want to build AI agents with engineered trust? Get your AI Trust Audit to identify gaps in your agent's guardrails and autonomy controls.
The Gap Between Capability and Control
AI agents can do more than traditional automation. They reason. They adapt. They make choices based on context.
That's the promise. It's also the risk.
Traditional software follows explicit rules. If-then logic. Predictable paths. You know what happens when a user clicks a button.
Agents don't work that way. They interpret. They infer. They generate responses you didn't hardcode.
This creates a new challenge: how do you trust something that thinks for itself?5
You can't audit every decision. You can't predict every edge case. You need a different approach.
What Trust Engineering Actually Means
Trust engineering isn't about making AI "safe" in some abstract sense. It's about building systems where you can verify behavior without micromanaging every action.
Here's what that looks like in practice:
Bounded autonomy. Your agent can make decisions, but only within defined limits. It can approve refunds up to $50. It can schedule meetings but not cancel them. It can draft emails but not send them without review.
You're not restricting intelligence. You're defining the sandbox.1
Transparent reasoning. When your agent makes a choice, you see why. Not just the output, but the logic chain.4 What data did it use? What alternatives did it consider? What confidence level did it assign?
This isn't about explainability for ethics committees. It's about debugging trust failures in real time.
Fail-safe defaults. When your agent encounters uncertainty, it doesn't guess. It escalates.11 It asks for human input. It logs the decision point for later review.
The best agents know what they don't know.
Guardrails That Scale With Autonomy
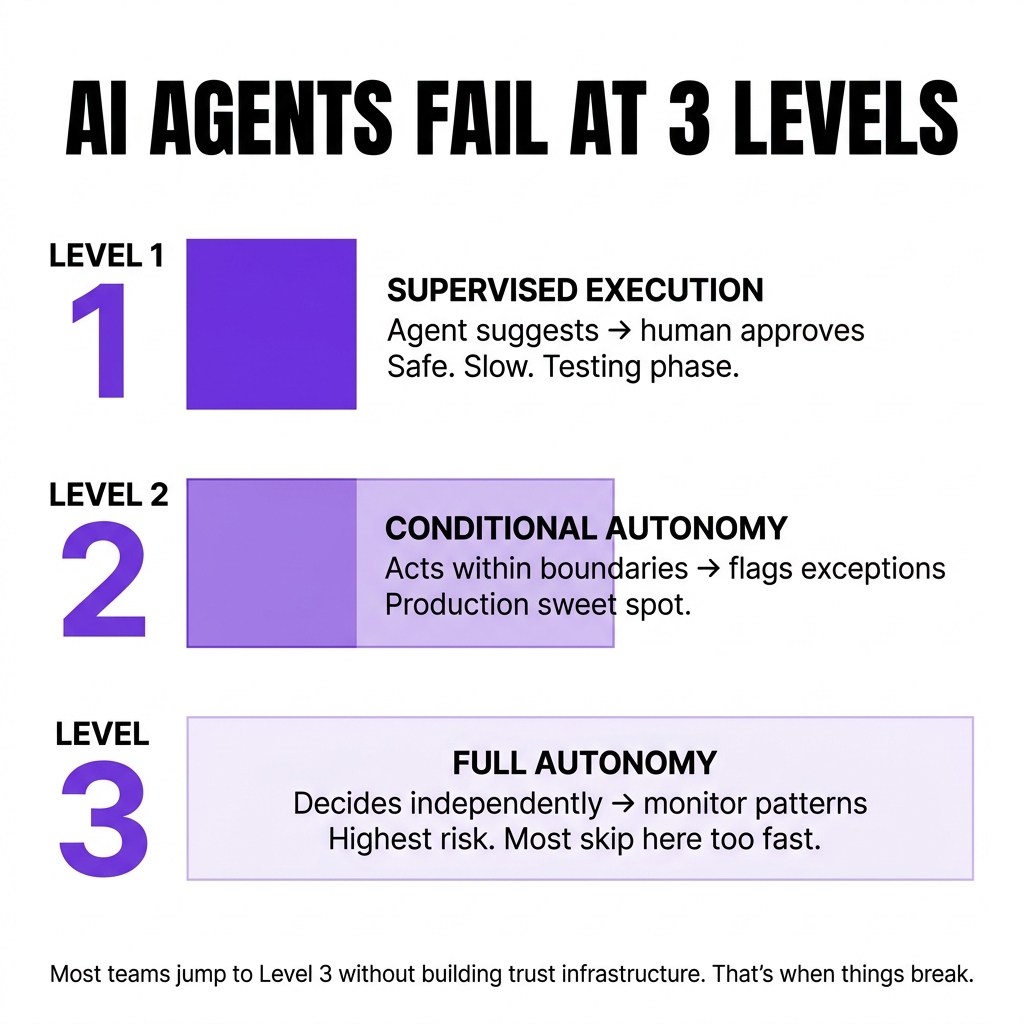
You need different guardrails at different autonomy levels.
Level 1: Supervised execution. Your agent suggests actions. Humans approve them. Every decision gets reviewed before it happens.
This works when you're testing. When you're learning what the agent gets right and what it misses. When the cost of error is high.
Level 2: Conditional autonomy. Your agent acts independently within preset boundaries.8 It handles routine cases automatically. It flags exceptions for human review.
This is where most production agents should live. Enough freedom to provide value. Enough constraint to prevent disasters.
Level 3: Full autonomy with monitoring. Your agent makes decisions without asking. You watch patterns, not individual actions. You intervene when metrics drift.
This only works when you've validated behavior across thousands of cases. When you have robust monitoring. When the domain is well-defined.
Most teams jump to Level 3 too fast. They want the efficiency gains without building the trust infrastructure first.
That's when things break.
The Monitoring Problem Nobody Talks About
You can't watch your agent make every decision. That defeats the purpose of automation.
But you can't ignore it either. You need selective attention.
Monitor patterns, not instances. Track error rates, not individual mistakes. Watch for drift in behavior over time.2,4
Set thresholds that trigger alerts.7 If your agent's approval rate suddenly drops 20%, something changed. If response times spike, investigate. If user complaints cluster around specific decision types, you found a gap.
You're not looking for perfection. You're looking for predictable imperfection.
When your agent fails in expected ways, you can plan for it. When it fails in novel ways, you have a trust problem.
Building Trust Through Constraints
The counterintuitive truth: constraints build trust faster than capabilities.1
When you limit what your agent can do, you make its behavior more predictable. When behavior is predictable, people trust it.
Start narrow. Give your agent one job. Let it master that before expanding scope.
A customer service agent that only handles returns? People will trust it. A customer service agent that handles everything? People will second-guess it.
You can always expand permissions later. You can't easily recover from a trust failure.
The Human-in-the-Loop Fallacy
Keeping humans in the loop sounds safe. It's often the opposite.
When humans review every AI decision, they stop paying attention. They rubber-stamp.9 They assume the AI is probably right.12
Then the AI makes a real mistake. The human doesn't catch it.10 And now you have two failures instead of one.
Better approach: Remove humans from routine decisions. Insert them at critical decision points. Make their role meaningful, not performative.5,9
Your agent handles 95% of cases automatically. Humans handle the 5% that matter most. Everyone focuses on what they're good at.
What Happens When Trust Breaks
Your agent will make mistakes. Plan for it.
The question isn't whether it fails. It's whether you can detect, diagnose, and recover when it does.
You need rollback mechanisms. Ways to undo automated decisions. Ways to compensate affected users. Ways to prevent the same error from happening again.
You need communication protocols. Who gets notified when something goes wrong? How quickly can you disable the agent? What's your message to users?
You need blameless post-mortems. What triggered the failure? What guardrail should have caught it? What changes prevent recurrence?
Trust isn't binary. It's a spectrum. Every failure either strengthens or weakens it, depending on how you respond.
The Real Cost of Under-Engineering Trust
When you skip trust engineering, you pay later.
You pay in manual review time. Someone has to check the agent's work because nobody trusts it.
You pay in limited adoption. Teams avoid using the agent for important tasks because they're not confident in the results.
You pay in recovery costs. When the agent makes a mistake, you spend hours fixing it and explaining it.
You pay in opportunity cost. You could have built something people actually rely on. Instead you built something people work around.
Trust engineering isn't overhead. It's the foundation that makes autonomy possible.
Where to Start
Pick one agent. One workflow. One decision type.
Define the boundaries. What can it decide? What must it escalate? What data can it access?
Build transparency. Log every decision with enough context to understand it later.
Set monitoring thresholds. What metrics indicate healthy behavior? What triggers investigation?
Test failure modes. What happens when the agent gets bad input? When it encounters edge cases? When external systems fail?
Start with low stakes. Prove the system works before expanding scope.
You're not building perfect AI. You're building trustworthy automation.
There's a difference.
Moving Forward
AI agents will handle more decisions over time. That's inevitable.
The teams that succeed won't be the ones with the most advanced models. They'll be the ones who engineered trust into the system from the start.
They'll know what their agents can handle. They'll know when to intervene. They'll know how to recover when things go wrong.
They'll build systems people actually trust, not just systems that technically work.
That's the difference between shipping an AI agent and shipping one that matters.
Build Trustworthy AI Agents That Scale
Engineering trust into AI agents isn't optional anymore—it's the foundation of successful automation. Explore AI Twin Brain to see how leading teams are building agents with proper guardrails and monitoring.
Ready to audit your current AI systems? Start your AI Trust Audit today and get actionable insights on where your agents need stronger trust engineering.
References
CIT Solutions. (2026). "How to Build High-Trust AI Agents for 2026." https://www.citsolutions.net/how-to-build-high-trust-ai-agents-for-2026/
Atlan. (2026). "AI Agent Risks & Guardrails: 2026 Enterprise Security Guide." https://atlan.com/know/ai-agent-risks-guardrails/
Authority Partners. (2026). "AI Agent Guardrails: Production Guide for 2026." https://authoritypartners.com/insights/ai-agent-guardrails-production-guide-for-2026/
N-iX. (2025). "AI Agent Observability: A Practical Framework for Reliable and Governed Agentic Systems." https://www.n-ix.com/ai-agent-observability/
Maxim AI. (2025). "5 Best Tools to Monitor AI Agents in 2025." https://www.getmaxim.ai/articles/5-best-tools-to-monitor-ai-agents-in-2025/
UptimeRobot. (2026). "AI Agent Monitoring: Best Practices, Tools & Metrics for 2026." https://uptimerobot.com/knowledge-hub/monitoring/ai-agent-monitoring-best-practices-tools-and-metrics/
Rubrik. "Agent Observability: How to Monitor AI Agents." https://www.rubrik.com/insights/ai-observability
MIT Press. (2026). "AI Agents Are Transforming Decision Making: What Leaders Should Know." Harvard Data Science Review, Issue 8.2. https://hdsr.mitpress.mit.edu/pub/fdzqkh85
Elementum AI. (2026). "Human-in-the-Loop Agentic AI: When You Need Both." https://www.elementum.ai/blog/human-in-the-loop-agentic-ai
Institute for Systems Integrity. (2026). "From Human-in-the-Loop to Human-with-Agency: Why AI Oversight Fails When Humans Are Present but Powerless." https://www.systemsintegrity.org/from-human-in-the-loop-to-human-with-agency-why-ai-oversight-fails-when-humans-are-present-but-powerless/
arXiv. "Agentic Metacognition: Designing a 'Self-Aware' Low-Code Agent for Failure Prediction and Human Handoff." arXiv:2509.19783. https://arxiv.org/pdf/2509.19783
International AI Safety Report. (2026). arXiv:2602.21012. https://arxiv.org/pdf/2602.21012
